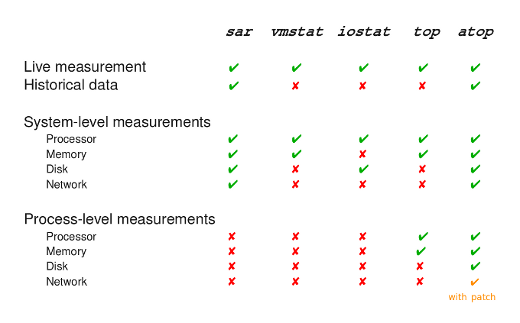
sar ‚ÄĒ –Ņ–ĺ–ļ–į–∑—č–≤–į–Ķ—ā –Ī–ĺ–Ľ–Ķ–Ķ —á–Ķ–ľ –ī–ĺ—Ā—ā–į—ā–ĺ—á–Ĺ—É—é –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—é –ĺ –Ĺ–Ķ–ĺ–Ī—Ö–ĺ–ī–ł–ľ—č—Ö –Ĺ–į–ľ —á–Ķ—ā—č—Ä–Ķ—Ö —Ä–Ķ—Ā—É—Ä—Ā–į—Ö —Ā–ł—Ā—ā–Ķ–ľ—č, —É–ľ–Ķ–Ķ—ā ¬ę–≤–ĺ–∑–≤—Ä–į—Č–į—ā—Ć—Ā—Ź –≤ –Ņ—Ä–ĺ—ą–Ľ–ĺ–Ķ¬Ľ, –Ĺ–ĺ –Ĺ–Ķ —É–ľ–Ķ–Ķ—ā —Ą–ĺ–ļ—É—Ā–ł—Ä–ĺ–≤–į—ā—Ć—Ā—Ź –Ĺ–į –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–į—Ö.
vmstat –ł iostat ‚ÄĒ –ľ–ĺ–≥—É—ā –ľ–ĺ–Ĺ–ł—ā–ĺ—Ä–ł—ā—Ć CPU, –Ņ–į–ľ—Ź—ā—Ć –ł –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł–Ķ –ī–ł—Ā–ļ–į —ā–ĺ–Ľ—Ć–ļ–ĺ –Ĺ–į —Ā–ł—Ā—ā–Ķ–ľ–Ĺ–ĺ–ľ —É—Ä–ĺ–≤–Ĺ–Ķ, –Ĺ–ĺ –Ĺ–Ķ –Ĺ–į —É—Ä–ĺ–≤–Ĺ–Ķ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–į, —ā–į–ļ–∂–Ķ –Ĺ–Ķ —É–ľ–Ķ—é—ā ¬ę–≤–ĺ–∑–≤—Ä–į—Č–į—ā—Ć—Ā—Ź –≤ –Ņ—Ä–ĺ—ą–Ľ–ĺ–Ķ¬Ľ.
top ‚ÄĒ –ļ–į–ļ –Ī–Ķ–∑—É—Ā–Ľ–ĺ–≤–Ĺ–ĺ —Ā–į–ľ–į—Ź –Ņ–ĺ–Ņ—É–Ľ—Ź—Ä–Ĺ–į—Ź —É—ā–ł–Ľ–ł—ā–į, –ľ–ĺ–Ĺ–ł—ā–ĺ—Ä–ł—ā CPU –ł –Ņ–į–ľ—Ź—ā—Ć –Ĺ–į —É—Ä–ĺ–≤–Ĺ–Ķ —Ā–ł—Ā—ā–Ķ–ľ—č –ł –Ĺ–į —É—Ä–ĺ–≤–Ĺ–Ķ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ–≤. –Ě–ĺ –ļ–į–ļ –ł –ľ–Ĺ–ĺ–≥–ł–Ķ –ī—Ä—É–≥–ł–Ķ –Ņ–ĺ–ļ–į–∑—č–≤–į–Ķ—ā —ā–ĺ–Ľ—Ć–ļ–ĺ —ā–Ķ–ļ—É—Č—É—é —Ā–ł—ā—É–į—Ü–ł—é, —Ā–į–ľ—č–ľ –≥–Ľ–į–≤–Ĺ—č–ľ –ľ–ł–Ĺ—É—Ā–ĺ–ľ –Ĺ–į –ľ–ĺ–Ļ –≤–∑–≥–Ľ—Ź–ī —ć—ā–ĺ —ā–ĺ, —á—ā–ĺ –Ķ–Ķ –Ņ–ĺ–ļ–į–∑–į–Ĺ–ł—Ź –Ĺ–Ķ –≤—Ā–Ķ–≥–ī–į —ā–ĺ—á–Ĺ—č, –ł—Ā–Ņ–ĺ–Ľ—Ć–∑—É—Ź —É—ā–ł–Ľ–ł—ā—É top –ľ—č –ľ–ĺ–∂–Ķ–ľ —Ā—ā–ĺ–Ľ–ļ–Ĺ—É—ā—Ć—Ā—Ź —Ā —ā–į–ļ–ĺ–Ļ –Ņ—Ä–ĺ–Ī–Ľ–Ķ–ľ–ĺ–Ļ: —Ā–ł—Ā—ā–Ķ–ľ–į –Ī—É–ī–Ķ—ā —É–ļ–į–∑—č–≤–į—ā—Ć –Ĺ–į–ľ —á—ā–ĺ –∑–į–Ĺ—Ź—ā—Ć 90% CPU, –į –Ĺ–į —Ā–į–ľ–ĺ–ľ –ī–Ķ–Ľ–Ķ —Ā—É–ľ–ľ–į –∑–į–≥—Ä—É–∂–Ķ–Ĺ–Ĺ–ĺ—Ā—ā–ł CPU –Ĺ–į —É—Ä–ĺ–≤–Ĺ–Ķ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ–≤ –Ī—É–ī–Ķ—ā 40% (—Ä–į–∑–Ĺ–ł—Ü–į –≤ 50% –Ņ—Ä–ĺ—Ü–Ķ–Ĺ—ā–ĺ–≤ —É–ļ–į–∑—č–≤–į–Ķ—ā, —á—ā–ĺ —Ā–ł—Ā—ā–Ķ–ľ–į –Ņ–ĺ–ļ–į–∑—č–≤–į—é—ā –Ĺ–į–ľ –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—é –ľ–Ķ–∂–ī—É –Ņ—Ä–Ķ–ī—č–ī—É—Č–ł–ľ –ł —ā–Ķ–ļ—É—Č–ł–ľ —Ā–Ĺ–ł–ľ–ļ–ĺ–ľ, —Ö–ĺ—ā—Ź —Ā–ł—Ā—ā–Ķ–ľ–į –≤ –Ņ—Ä–ł–Ĺ—Ü–ł–Ņ–Ķ —É–∂–Ķ —Ā–≤–ĺ–Ī–ĺ–ī–Ĺ–į). –Ę.–Ķ –ī–ĺ—Ā—ā–ĺ–≤–Ķ—Ä–Ĺ–ĺ—Ā—ā—Ć –ł –ł–Ĺ—Ą–ĺ—Ä–ľ–į—ā–ł–≤–Ĺ–ĺ—Ā—ā—Ć –Ĺ–Ķ–ľ–Ĺ–ĺ–≥–ĺ —Ö—Ä–ĺ–ľ–į–Ķ—ā.
–Ě–ł–∂–Ķ –Ņ—Ä–ł–≤–Ķ–ī–Ķ–Ĺ–į —ā–į–Ī–Ľ–ł—Ü–į —Ā—Ä–į–≤–Ĺ–Ķ–Ĺ–ł—Ź —ć—ā–ł—Ö —Ā–ł—Ā—ā–Ķ–ľ –Ņ–ĺ —Ö–į—Ä–į–ļ—ā–Ķ—Ä–ł—Ā—ā–ł–ļ–į–ľ.
–£—ā–ł–Ľ–ł—ā–į atop –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é —É–ľ–Ķ–Ķ—ā –Ņ–ĺ–ļ–į–∑—č–≤–į—ā—Ć –∑–į–≥—Ä—É–∑–ļ—É –Ņ–ĺ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ—Ä—É, –Ņ–į–ľ—Ź—ā–ł, –ī–ł—Ā–ļ–į–ľ –ł —Ā–Ķ—ā–ł. –Ę–į–ļ–∂–Ķ –ī–ĺ—Ā—ā—É–Ņ–Ķ–Ĺ –Ņ–į—ā—á, –ļ–ĺ—ā–ĺ—Ä—č–Ļ –Ī—É–ī–Ķ—ā –Ņ–ĺ–ļ–į–∑—č–≤–į—ā—Ć –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł–Ķ —Ā–Ķ—ā–ł –Ņ–ĺ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–į–ľ. –ü–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é —Ā—ā–į–Ĺ–ī–į—Ä—ā–Ĺ—č–ľ –≤—č–≤–ĺ–ī–ĺ–ľ –ļ–ĺ–ľ–į–Ĺ–ī—č —Ź–≤–Ľ—Ź–Ķ—ā—Ā—Ź —Ā–Ľ–Ķ–ī—É—é—Č–į—Ź –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—Ź:
–ö–į–ļ –ł –≤ —Ā—ā–į–Ĺ–ī–į—Ä—ā–Ĺ–ĺ–ľ –≤—č–≤–ĺ–ī–Ķ top —ć–ļ—Ä–į–Ĺ —Ä–į–∑–ī–Ķ–Ľ–Ķ–Ĺ –Ĺ–į –ī–≤–Ķ –Ņ–ĺ–Ľ–ĺ–≤–ł–Ĺ—č, –≤ –Ņ–Ķ—Ä–≤–ĺ–Ļ –ł–∑ –Ĺ–ł—Ö —É–ļ–į–∑–į–Ĺ—č –ī–į–Ĺ–Ĺ—č–Ķ –ĺ —Ā–ł—Ā—ā–Ķ–ľ–Ķ, –į –≤–ĺ –≤—ā–ĺ—Ä–ĺ–Ļ –ī–į–Ĺ–Ĺ—č–Ķ –Ņ–ĺ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–į–ľ.
–í –≤–Ķ—Ä—Ö–Ĺ–Ķ–Ļ –Ņ–ĺ–Ľ–ĺ–≤–ł–Ĺ–Ķ –≤–ł–ī–Ĺ–į –Ĺ–Ķ —ā–ĺ–Ľ—Ć–ļ–ĺ –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—Ź –Ņ–ĺ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ—Ä—É –ł –Ņ–ĺ –Ņ–į–ľ—Ź—ā–ł –ļ–į–ļ –≤ —Ā—ā–į–Ĺ–ī–į—Ä—ā–Ĺ–ĺ–ľ –≤—č–≤–ĺ–ī–Ķ top, –į –Ķ—Č–Ķ –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—Ź –ļ–į—Ā–į—ā–Ķ–Ľ—Ć–Ĺ–ĺ —Ā–Ķ—ā–ł –ł –ī–ł—Ā–ļ–ĺ–≤. –ē—Ā–Ľ–ł –ľ—č –ĺ–Ī—Ä–į—ā–ł–ľ –≤–Ĺ–ł–ľ–į–Ĺ–ł–Ķ –Ĺ–į 2 —Ā—ā—Ä–ĺ–ļ—É –ī–į–Ĺ–Ĺ–ĺ–≥–ĺ –≤—č–≤–ĺ–ī–į, –Ņ—Ä–ĺ—Ā—É–ľ–ľ–ł—Ä–ĺ–≤–į–≤ –∑–Ĺ–į—á–Ķ–Ĺ–ł—Ź (3+2+0+195+0) –ľ—č –Ņ–ĺ–Ľ—É—á–ł–ľ 200% ‚ÄĒ —ć—ā–ĺ –ĺ–∑–Ĺ–į—á–į–Ķ—ā, —á—ā–ĺ —Ā–ł—Ā—ā–Ķ–ľ–į —Ź–≤–Ľ—Ź–Ķ—ā—Ā—Ź 2 –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ—Ä–Ĺ–ĺ–Ļ, –ł –ļ–į–∂–ī—č–Ļ –ł–∑ –Ĺ–ł—Ö –ł–ľ–Ķ–Ķ—ā –Ņ–ĺ 100%, –Ĺ–ł–∂–Ķ –ī–į–Ķ—ā—Ā—Ź –ī–Ķ–Ľ–Ķ–Ĺ–ł–Ķ –Ņ–ĺ –ļ–į–∂–ī–ĺ–ľ—É –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ—Ä—É, –Ĺ–į —Ā–ļ–ĺ–Ľ—Ć–ļ–ĺ —ā–ĺ—ā –ł–Ľ–ł –ł–Ĺ–ĺ–Ļ –∑–į–Ĺ—Ź—ā. –Ě–ł–∂–Ķ –Ņ–ĺ—Ā–Ľ–Ķ —ć—ā–ł—Ö —Ā—ā—Ä–ĺ–ļ —É–ļ–į–∑–į–Ĺ–į –ĺ–Ņ–Ķ—Ä–į—ā–ł–≤–Ĺ–į—Ź –Ņ–į–ľ—Ź—ā—Ć, –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—Ź –Ņ–ĺ –ī–ł—Ā–ļ–į–ľ, –ł —Ā–Ķ—ā–Ķ–≤—č–ľ –ł–Ĺ—ā–Ķ—Ä—Ą–Ķ–Ļ—Ā–į–ľ.
–Ď–ĺ–Ľ–Ķ–Ķ –Ņ–ĺ–ī—Ä–ĺ–Ī–Ĺ–ĺ–Ķ –ĺ–Ņ–ł—Ā–į–Ĺ–ł–Ķ –ļ–į–∂–ī–ĺ–≥–ĺ —Ā—ā–ĺ–Ľ–Ī—Ü–į –ľ–ĺ–∂–Ĺ–ĺ –Ĺ–į–Ļ—ā–ł –≤ man —Ā—ā—Ä–į–Ĺ–ł—Ü–Ķ –ļ –ī–į–Ĺ–Ĺ–ĺ–Ļ —É—ā–ł–Ľ–ł—ā–Ķ, –ļ—Ā—ā–į—ā–ł –Ĺ–į —Ä–Ķ–ī–ļ–ĺ—Ā—ā—Ć –Ņ–ĺ–ī—Ä–ĺ–Ī–Ĺ–ĺ–Ķ –ĺ–Ņ–ł—Ā–į–Ĺ–ł–Ķ.
–ē—Ā—ā–Ķ—Ā—ā–≤–Ķ–Ĺ–Ĺ–ĺ –ľ—č –ľ–ĺ–∂–Ķ–ľ –ľ–Ķ–Ĺ—Ź—ā—Ć –Ķ–Ķ –≤–ł–ī —ā–į–ļ –ļ–į–ļ –Ĺ–į–ľ –∑–į—Ö–ĺ—á–Ķ—ā—Ā—Ź –ł—Ā–Ņ–ĺ–Ľ—Ć–∑—É—Ź –≥–ĺ—Ä—Ź—á–ł–Ķ –ļ–Ľ–į–≤–ł—ą–ł, –Ĺ–ł–∂–Ķ —Ź —É–ļ–į–∑–į–Ľ –Ĺ–į–ł–Ī–ĺ–Ľ–Ķ–Ķ –ł–Ĺ—ā–Ķ—Ä–Ķ—Ā–Ĺ—č–Ķ –ł–∑ –Ĺ–ł—Ö,
m ‚ÄĒ –≤—č—Ā—ā—Ä–ĺ–ł—ā –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā—č –Ņ–ĺ –∑–į–Ĺ—Ź—ā–ĺ–Ļ –Ņ–į–ľ—Ź—ā–ł
d ‚ÄĒ –Ņ–ĺ—Ā—ā—Ä–ĺ–ł—ā –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā—č –Ņ–ĺ –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł—é –ī–ł—Ā–ļ–į
n ‚ÄĒ –≤—č—Ā—ā—Ä–ĺ–ł—ā –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā—č –Ņ–ĺ –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł—é —Ā–Ķ—ā–ł (–ī–ĺ—Ā—ā—É–Ņ–Ĺ–ĺ —ā–ĺ–Ľ—Ć–ļ–ĺ —Ā —É—Ā—ā–į–Ĺ–ĺ–≤–Ľ–Ķ–Ĺ–Ĺ—č–ľ –Ņ–į—ā—á–Ķ–ľ)
v ‚ÄĒ –Ņ–ĺ–ļ–į–∂–Ķ—ā –Ī–ĺ–Ľ–Ķ–Ķ –Ņ–ĺ–ī—Ä–ĺ–Ī–Ĺ—É—é –ł–Ĺ—Ą–ĺ—Ä–ľ–į—Ü–ł—é –ĺ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–į—Ö (–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā–Ķ–Ľ—Ź, –ī–į—ā—É –ł –≤—Ä–Ķ–ľ—Ź –Ĺ–į—á–į–Ľ–į –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–į)
u ‚ÄĒ –≤—č—Ā—ā—Ä–ĺ–ł—ā —ā–į–Ī–Ľ–ł—Ü—É –Ņ–ĺ —Ā–į–ľ—č–ľ –Ņ—Ä–ĺ–∂–ĺ—Ä–Ľ–ł–≤—č–ľ –Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā–Ķ–Ľ—Ź–ľ
–ė—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł–Ķ shift+(d,m,n) –≤—č—Ā—ā—Ä–ĺ–ł—ā —ā–Ķ–ļ—É—Č–ł–Ļ —Ā–Ņ–ł—Ā–ĺ–ļ –Ņ–ĺ –≤—č—ą–Ķ —É–ļ–į–∑–į–Ĺ–Ĺ—č–ľ –Ņ–į—Ä–į–ľ–Ķ—ā—Ä–į–ľ.
i ‚ÄĒ –ł–∑–ľ–Ķ–Ĺ–Ķ–Ĺ–ł–Ķ –≤—Ä–Ķ–ľ–Ķ–Ĺ–ł –Ņ—Ä–ĺ–≤–Ķ—Ä–ļ–ł, –Ņ–ĺ —É–ľ–ĺ–Ľ—á–į–Ĺ–ł—é 10 —Ā–Ķ–ļ—É–Ĺ–ī.
g ‚ÄĒ –≤–Ķ—Ä–Ĺ–Ķ—ā –≤—Ā–Ķ –≤ –ī–Ķ—Ą–ĺ–Ľ—ā–Ĺ—č–Ļ –≤—č–≤–ĺ–ī.
–Ę–Ķ–Ņ–Ķ—Ä—Ć –ī–į–≤–į–Ļ—ā–Ķ –Ņ–ĺ—Ā–ľ–ĺ—ā—Ä–ł–ľ –ļ–į–ļ –≤—Ā–Ķ –∂–Ķ –Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į—ā—Ć—Ā—Ź —Ą—É–Ĺ–ļ—Ü–ł–Ķ–Ļ ¬ę–≤–ĺ–∑–≤—Ä–į—ā–į –≤ –Ņ—Ä–ĺ—ą–Ľ–ĺ–Ķ¬Ľ, —É —É—ā–ł–Ľ–ł—ā—č atop –Ņ—Ä–ł —Ā—ā–į–Ĺ–ī–į—Ä—ā–Ĺ–ĺ–Ļ —É—Ā—ā–į–Ĺ–ĺ–≤–ļ–Ķ –Ķ—Ā—ā—Ć —ā–į–ļ–į—Ź –Ņ–ĺ–Ľ–Ķ–∑–Ĺ–į—Ź ¬ę—Ą–ł—á–į¬Ľ, –ļ–ĺ—ā–ĺ—Ä–į—Ź –≤–ļ–Ľ—é—á–į–Ķ—ā –Ĺ–ĺ—á–Ĺ–ĺ–Ķ –Ľ–ĺ–≥–ł—Ä–ĺ–≤–į–Ĺ–ł–Ķ –Ņ—Ä–ĺ–ł–∑–≤–ĺ–ī–ł—ā–Ķ–Ľ—Ć–Ĺ–ĺ—Ā—ā–ł —Ā–ł—Ā—ā–Ķ–ľ—č. –£—ā–ł–Ľ–ł—ā–į –Ņ–ĺ –ī–Ķ—Ą–ĺ–Ľ—ā—É —Ā–Ĺ–ł–ľ–į–Ķ—ā –Ņ–ĺ–ļ–į–∑–į–Ĺ–ł—Ź –ļ–į–∂–ī—č–Ķ 10 –ľ–ł–Ĺ—É—ā, –ł —Ā–Ī—Ä–į—Ā—č–≤–į–Ķ—ā –ł—Ö –≤ –Ľ–ĺ–≥ /var/log/atop-YYYYMMDD.
****
%iowait ‚Äď –Ņ–ĺ–ļ–į–∑–į—ā–Ķ–Ľ—Ć, –ĺ–∑–Ĺ–į—á–į—é—Č–ł–Ļ –Ņ—Ä–ĺ—Ü–Ķ–Ĺ—ā–Ĺ–ĺ–Ķ —Ā–ĺ–ĺ—ā–Ĺ–ĺ—ą–Ķ–Ĺ–ł–Ķ –≤—Ä–Ķ–ľ–Ķ–Ĺ–ł –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ—Ä–į, –Ņ–ĺ—ā—Ä–į—á–Ķ–Ĺ–Ĺ–ĺ–Ķ –Ĺ–į –ĺ–∂–ł–ī–į–Ĺ–ł–Ķ –≤–≤–ĺ–ī–į/–≤—č–≤–ĺ–ī–į.
–í—č—Ā–ĺ–ļ–ł–Ļ %iowait –≥–ĺ–≤–ĺ—Ä–ł—ā –ĺ —ā–ĺ–ľ, —á—ā–ĺ —Ā–ł—Ā—ā–Ķ–ľ–į –ĺ–≥—Ä–į–Ĺ–ł—á–Ķ–Ĺ–į –≤–ĺ–∑–ľ–ĺ–∂–Ĺ–ĺ—Ā—ā—Ź–ľ–ł –ī–ł—Ā–ļ–ĺ–≤–ĺ–Ļ –Ņ–į–ľ—Ź—ā–ł, –≤—č–Ņ–ĺ–Ľ–Ĺ—Ź—Ź –ľ–Ĺ–ĺ–∂–Ķ—Ā—ā–≤–ĺ –ĺ–Ņ–Ķ—Ä–į—Ü–ł–Ļ –ī–ł—Ā–ļ–ĺ–≤–ĺ–≥–ĺ –≤–≤–ĺ–ī–į-–≤—č–≤–ĺ–ī–į, —á—ā–ĺ –Ņ—Ä–ł–≤–ĺ–ī–ł—ā –ļ –∑–į–ľ–Ķ–ī–Ľ–Ķ–Ĺ–ł—é —Ä–į–Ī–ĺ—ā—č —Ā–ł—Ā—ā–Ķ–ľ—č.
LA –ľ–ĺ–∂–Ķ—ā –Ī—č—ā—Ć —Ö–ĺ—Ä–ĺ—ą–ł–ľ –ĺ–Ņ–ĺ–≤–Ķ—Č–Ķ–Ĺ–ł–Ķ–ľ ‚ÄĒ –Ķ—Ā–Ľ–ł –≤—č—Ä–į—Ā—ā–į–Ķ—ā –≤ 10 —Ä–į–∑ –≤—č—ą–Ķ –ĺ–Ī—č—á–Ĺ–ĺ–≥–ĺ ‚ÄĒ –Ĺ–į–ī–ĺ —Ā—Ä–ĺ—á–Ĺ–ĺ —Ā–Ņ–į—Ā–į—ā—Ć —Ā–Ķ—Ä–≤–Ķ—Ä –Ņ–ĺ–ļ–į –ļ–ĺ–Ĺ—ā—Ä–ĺ–Ľ—Ć –Ĺ–Ķ –Ņ–ĺ—ā–Ķ—Ä—Ź–Ľ. –ö–į–ļ –Ņ—Ä–į–≤–ł–Ľ—Ć–Ĺ–ĺ –∑–į–ľ–Ķ—á–į–Ľ–ł –Ņ—Ä–ĺ NFS (–ĺ—Ā–ĺ–Ī–Ķ–Ĺ–Ĺ–ĺ —Ā –hard) –Ī—č–≤–į–Ķ—ā –ł 1200 LA –Ņ—Ä–ł –ĺ—ā–Ľ–ł—á–Ĺ–ĺ —Ä–į–Ī–ĺ—ā–į—é—Č–Ķ–ľ —Ā–Ķ—Ä–≤–Ķ—Ä–Ķ.
–Ę–į–ļ –∂–Ķ –Ĺ–Ķ–Ņ–Ľ–ĺ—Ö–ł–ľ –ļ—Ä–ł—ā–Ķ—Ä–ł–Ķ–ľ –ĺ–Ņ–į—Ā–Ĺ–ĺ—Ā—ā–ł —Ź–≤–Ľ—Ź–Ķ—ā—Ā—Ź CPU idle ‚ÄĒ –Ķ—Ā–Ľ–ł —Ā—Ä–Ķ–ī–Ĺ–Ķ–Ķ –∑–Ĺ–į—á–Ķ–Ĺ–ł–Ķ –∑–į –ī–Ķ–Ĺ—Ć –ľ–Ķ–Ĺ—Ć—ą–Ķ 30% –Ĺ–į–ī–ĺ –Ņ–ĺ —ć—ā–ĺ–ľ—É –Ņ–ĺ–≤–ĺ–ī—É —á—ā–ĺ-—ā–ĺ –Ņ—Ä–Ķ–ī–Ņ—Ä–ł–Ĺ—Ź—ā—Ć.
–ě—á–Ķ–Ĺ—Ć —á–į—Ā—ā–ĺ LA —Ź–≤–Ľ—Ź–Ķ—ā—Ā—Ź —É–ļ–į–∑–į—ā–Ķ–Ľ–Ķ–ľ –Ĺ–į –Ĺ–Ķ—Ö–≤–į—ā–ļ—É –Ņ–į–ľ—Ź—ā–ł ‚ÄĒ –ľ–ĺ–Ĺ–ł—ā–ĺ—Ä–ł—ā—Ć —Ā–≤–ĺ–Ī–ĺ–ī–Ĺ—É—é –Ņ–į–ľ—Ź—ā—Ć –≤ –Ľ–ł–Ĺ—É–ļ—Ā–Ķ –ī–Ķ–Ľ–ĺ –Ķ—Č–Ķ –ľ–Ķ–Ĺ–Ķ–Ķ –Ī–Ľ–į–≥–ĺ–ī–į—Ä–Ĺ–ĺ–Ķ —á–Ķ–ľ –≥–į–ī–į—ā—Ć –Ĺ–į LA, –Ĺ–ĺ –≤—Ā–Ķ –≤–ľ–Ķ—Ā—ā–Ķ —Ā–ĺ—Ā—ā–į–≤–Ľ—Ź–Ķ—ā —Ā–ł–ľ–Ņ—ā–ĺ–ľ. –ü–Ķ—Ä–≤–Ķ–Ļ—ą–Ķ–Ķ –ī–Ķ–Ľ–ĺ —ć—ā–ĺ –∑–į–Ņ—É—Ā—ā–ł—ā—Ć ‘vmstat 1’ –ł —Ā–ľ–ĺ—ā—Ä–Ķ—ā—Ć –ļ–ĺ–Ľ–ĺ–Ĺ–ļ–ł r,b,si –ł so. –ē—Ā–Ľ–ł –≤ b –ļ–į–ļ–ł–Ķ –Ĺ–Ķ–į–ī–Ķ–ļ–≤–į—ā–Ĺ—č–Ķ —Ü–ł—Ą—Ä—č, –į –≤ r –Ķ–ī–ł–Ĺ–ł—á–ļ–ł –ł –≤ —ā–ĺ –∂–Ķ –≤—Ä–Ķ–ľ—Ź –≤ si/so —Ā—á–Ķ—ā—á–ł–ļ –ł–ī–Ķ—ā –Ĺ–į —ā—č—Ā—Ź—á–ł –ł –ī–Ķ—Ā—Ź—ā–ļ–ł —ā—č—Ā—Ź—á ‚ÄĒ –Ĺ–į–ī–ĺ –Ņ—Ä—Ź–ľ —Č–į–∑ —É–Ī–ł–≤–į—ā—Ć –ļ–į–ļ–ĺ–Ļ-—ā–ĺ –∂–ł—Ä–Ĺ—č–Ļ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā, –į —ā–ĺ –ľ–ĺ–∂–Ĺ–ĺ –Ņ–ĺ—ā–Ķ—Ä—Ź—ā—Ć –ļ–ĺ–Ĺ—ā—Ä–ĺ–Ľ—Ć.
–ó–į—á–į—Ā—ā—É—é –∑–į–≤–Ķ—Ä—ą–Ķ–Ĺ–ł–Ķ —ć—ā–ł—Ö –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ–≤ –Ĺ–Ķ–≤–ĺ–∑–ľ–ĺ–∂–Ĺ–ĺ —ā.–ļ. —ć—ā–ĺ uninterruptible sleep (usually IO). –ü–ĺ–ľ–ĺ–≥–į–Ķ—ā –Ņ–Ķ—Ä–Ķ–∑–į–≥—Ä—É–∑–ļ–į.
–ú–ĺ—Ď –≥—Ä—É–Ī–ĺ–Ķ –ĺ–Ņ—Ä–Ķ–ī–Ķ–Ľ–Ķ–Ĺ–ł–Ķ Load –≤ Linux ‚ÄĒ —ć—ā–ĺ —á–ł—Ā–Ľ–ĺ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ–≤, –Ĺ–į—Ö–ĺ–ī—Ź—Č–ł—Ö—Ā—Ź –≤ —Ā–ĺ—Ā—ā–ĺ—Ź–Ĺ–ł–ł R (running or runnable (on run queue)) + —á–ł—Ā–Ľ–ĺ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ–≤ –≤ —Ā–ĺ—Ā—ā–ĺ—Ź–Ĺ–ł–ł D (uninterruptible sleep (usually IO)). Load average —É—Ā—Ä–Ķ–ī–Ĺ—Ź–Ķ—ā —ć—ā–ł –∑–Ĺ–į—á–Ķ–Ĺ–ł—Ź –Ņ–ĺ —Ö–ł—ā—Ä–ĺ–Ļ —Ą–ĺ—Ä–ľ—É–Ľ–Ķ (–ļ–į–∂–Ķ—ā—Ā—Ź, —ć—ā–ĺ —ć–ļ—Ā–Ņ–ĺ–Ĺ–Ķ–Ĺ—Ü–ł–į–Ľ—Ć–Ĺ–ĺ –≤–∑–≤–Ķ—ą–Ķ–Ĺ–Ĺ–ĺ–Ķ —Ā–ļ–ĺ–Ľ—Ć–∑—Ź—Č–Ķ–Ķ —Ā—Ä–Ķ–ī–Ĺ–Ķ–Ķ).
–ü–ĺ—Ā–ľ–ĺ—ā—Ä–Ķ—ā—Ć —Ā—ā–į—ā—É—Ā—č –ľ–ĺ–∂–Ĺ–ĺ —á–Ķ—Ä–Ķ–∑ ps.
–°—ā–į—ā—Ć—Ź –≤ —ā–į–ļ–ĺ–ľ –≤–ł–ī–Ķ –Ĺ–Ķ –ī–į—Ď—ā –Ĺ–ł–ļ–į–ļ–ĺ–≥–ĺ –Ņ–ĺ–Ĺ–ł–ľ–į–Ĺ–ł—Ź –ĺ LA –≤ Linux.
–ú–į–Ľ–ĺ —ā–ĺ–≥–ĺ, LA –≤ Linux –≤–ĺ–ĺ–Ī—Č–Ķ –Ĺ–Ķ –ł–Ĺ—Ą–ĺ—Ä–ľ–į—ā–ł–≤–Ķ–Ĺ, –ł–Ī–ĺ —Ā–ľ–Ķ—ą–ł–≤–į–Ķ—ā –ĺ—á–Ķ—Ä–Ķ–ī—Ć I/O –ł –ĺ—á–Ķ—Ä–Ķ–ī—Ć –Ĺ–į –≤—č–Ņ–ĺ–Ľ–Ĺ–Ķ–Ĺ–ł–Ķ –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ—Ä–ĺ–ľ. –ö–į–ļ —Ź —É–∂–Ķ –≥–ĺ–≤–ĺ—Ä–ł–Ľ, —Ā–ľ–ĺ—ā—Ä–Ķ—ā—Ć –Ĺ—É–∂–Ĺ–ĺ –≤ ps.
dstat -tldnpms 10
–ü—Ä–ł —ć—ā–ĺ–ľ –Ī—É–ī–Ķ—ā –≤—č–≤–ĺ–ī–ł—ā—Ć—Ā—Ź:
-
—ā–Ķ–ļ—É—Č–Ķ–Ķ –≤—Ä–Ķ–ľ—Ź ‚Ästt
-
—Ā—Ä–Ķ–ī–Ĺ—Ź—Ź –∑–į–≥—Ä—É–∑–ļ–į —Ā–ł—Ā—ā–Ķ–ľ—č ‚Ästl
-
–ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł—Ź –ī–ł—Ā–ļ–ĺ–≤ ‚Ästd
-
–∑–į–≥—Ä—É–∑–ļ–į —Ā–Ķ—ā–Ķ–≤—č—Ö —É—Ā—ā—Ä–ĺ–Ļ—Ā—ā–≤ ‚Ästn
-
–į–ļ—ā–ł–≤–Ĺ–ĺ—Ā—ā—Ć –Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ–≤ ‚Ästp
-
–ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł–Ķ –Ņ–į–ľ—Ź—ā–ł ‚Ästm
-
–ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł–Ķ –Ņ–ĺ–ī–ļ–į—á–ļ–ł ‚Ästs
-
—Ā –ł–Ĺ—ā–Ķ—Ä–≤–į–Ľ–ĺ–≤ –≤¬†10¬†—Ā–Ķ–ļ—É–Ĺ–ī
–ē—Č–Ķ –Ņ—Ä–ł–ľ–Ķ—Ä –ł—Ā–Ņ–ĺ–Ľ—Ć–∑–ĺ–≤–į–Ĺ–ł—Ź. –í—č–≤–ĺ–ī —Ā–į–ľ—č—Ö¬†–Ņ—Ä–ĺ–∂–ĺ—Ä–Ľ–ł–≤—č—Ö¬†–Ņ—Ä–ĺ—Ü–Ķ—Ā—Ā–ĺ–≤:
dstat -tl -M top-cpu,top-io -d -M top-mem -m 10
dstat -tl –top-cpu -d –top-io -n –top-mem -m 10

